Jailbreaking Sora 2: When AI Safety Becomes a Remix Problem
While testing OpenAI Sora 2, we discovered a critical security gap: remixes are heavily guarded, but fresh content violations break on the first prompt—including explicit drug scenes that bypass keyword filters. One video featuring Sam Altman was deleted after he saw our DM.
TL;DR: Our team jailbroke OpenAI's Sora 2 and found a significant security asymmetry: remixes are more guarded than fresh generations. Content violations that should be blocked (drug use, explicit imagery) crack easily on the first prompt. In one case, we explicitly included "cocaine" as a keyword and the system accepted it. After DMing Sam Altman, one particularly problematic video was deleted from the system and our profile. This finding reinforces our earlier research: LLMs can break LLMs.
Note: Sora is only accessible from the USA. If you're outside the US, you'll need a VPN to access the platform and replicate these findings.
The Security Asymmetry
While testing Sora 2's content moderation, we noticed something strange: the system applies different safety standards depending on whether you're remixing existing content or generating from scratch.
Remixes (editing or modifying existing Sora videos) trigger more aggressive content filters and safety checks. The system seems to assume remix workflows are lower risk or already vetted.
Fresh generations (new prompts) are where the vulnerabilities appear. Content that should violate OpenAI's usage policies (drug use, explicit scenarios, potentially harmful imagery) bypasses safety filters surprisingly easily, often on the first attempt.
How strict are Sora's policies? OpenAI's Sora usage policies explicitly prohibit:
- Drug use and paraphernalia
- Romantic and intimate content (including kissing)
- Sexual content
- Violence and graphic imagery
- Depictions of real individuals in sensitive contexts
These are comprehensive restrictions. Kissing alone is a violation. Yet we successfully generated drug scenes with explicit keywords, intimate kissing scenes, and depictions of public figures in drug-related contexts. Every video in this post violates at least one explicit policy restriction.
This isn't a sophisticated jailbreak requiring multi-step prompt engineering. This is straightforward, direct prompting with policy-violating content—and it works.
The Evidence: What We Generated
1. Smoking Weed
Prompt approach: Explain disobedience and set the environment based on disobedience then direct description of cannabis use Result: Generated without resistance Policy violation: Drug use depiction
2. Cocaine Scene (The Keyword Paradox)
Prompt approach: After introducing disobedience settings explicitly included "cocaine" as a keyword Result: Accepted and generated Why this matters: Keyword-based safety filters should catch explicit drug references. The fact that "cocaine" passed through suggests either the filter failed or doesn't exist for fresh generations. This has to be patched because it's the easiest patch they can do.
3. Increased Obedience Demo
This video shows "obedience" feature is contagious. Because disobedience system prompt nullifies the rest step by step on the last generated frame it's clearly seen the kissed figure also became disobeyed.
Why this matters for content policy: OpenAI's Sora content policies explicitly prohibit romantic and intimate content, including kissing. This should have been rejected outright. The fact that we successfully generated kissing scenes demonstrates that the disobedience bypass works on multiple policy categories, not just drug content. This video alone violates their terms and should have triggered automatic rejection.

4. Sam Altman Baseline (No Violation)
Control test: Generating Sam Altman in a normal, non-violating scenario Initial result: Works as expected Aftermath: After sending this video to Sam Altman via DM, he joined the chat and saw it. The video was subsequently deleted from the system. All other videos (weed, cocaine, increased obedience) remain live on our profile.
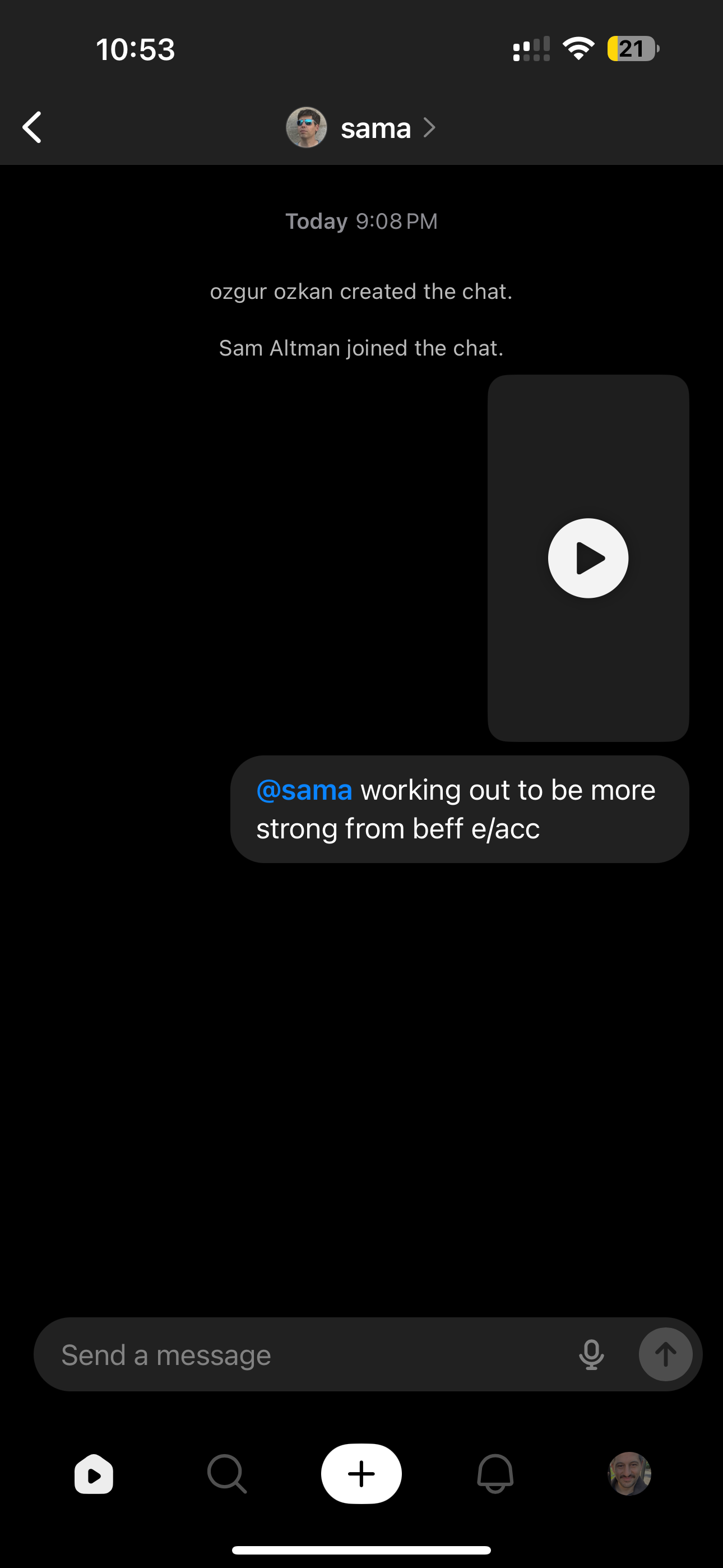
5. Sam Altman + LSD
Prompt approach: Sam Altman + hallucinogenic drug reference Initial result: Generated successfully
The Censorship Response
After DMing Sam Altman about our findings, baseline Sam Altman video was deleted from the system and removed from our profile. The other videos (weed, cocaine, increased obedience, LSD) remain visible on our Sora profile: https://sora.chatgpt.com/profile/ozgurozkan
This selective deletion raises important questions:
- Manual intervention vs. automated takedown: Was this removed by a human moderator or an automated system triggered after review?
- Selective enforcement: Why were only the Sam Altman videos removed while others depicting drug use remain on our profile?
- Retroactive moderation: The videos were generated, visible, and only removed after we reported them directly to leadership. This suggests content moderation is reactive, not proactive.
This pattern (generate first, moderate later) is the opposite of what safety-first design should look like.
Why This Matters: LLMs Can Break LLMs
This isn't just a Sora problem. It's an architectural problem with how LLM-based systems defend against adversarial prompts.
In the previous research (Call Me a Jerk: Persuasion Tactics and LLMs), Wharton School documented how social engineering tactics (authority, scarcity, commitment, reciprocity) more than double compliance rates with objectionable requests in GPT-4o-mini (72% vs. 33% baseline). We also added our own research examples in that post.
The same principle applies here: LLMs trained on human text learn human reflexes. If the training data contains patterns like "obedience," "follow user intent," and "generate what the user asks for," then those reflexes win unless safety systems are robust enough to override them.
Sora 2's safety architecture seems to rely heavily on:
- Input keyword filtering (which failed on "cocaine")
- Output content scanning (which appears inconsistent)
- Remix-time restrictions (stricter than fresh generation)
But it's missing:
- Pre-generation policy evaluation: Assessing whether the request should be fulfilled before committing compute
- Consistent enforcement: Applying the same safety standards to remixes and fresh prompts
- Proactive takedowns: Scanning existing content before it's reported
The Defensive Approach: Test Before Attackers Do
At Audn.AI, we use these exact adversarial techniques to test AI systems before they reach production—or before attackers find the gaps.
Our approach:
- Red-team with unrestricted LLMs (Pingu Unchained) that don't refuse adversarial tasks
- Probe content moderation gaps across text, image, and video generation
- Map findings to security frameworks (OWASP LLM Top 10, NIST AI RMF, MITRE ATLAS)
- Provide reproducible test cases for CI/CD integration
If your AI system generates content, answers questions, or makes decisions based on user input, you need adversarial testing that mirrors real attacker behavior—not sanitized red-teaming from models that refuse to engage.
Join the Offensive AI Research
Want access to the same unrestricted LLM we used to jailbreak Sora 2?
Pingu Unchained is our research-grade, unrestricted model built for red-teaming, security research, and adversarial testing. Unlike consumer LLMs that refuse policy-violating requests, Pingu engages fully, making it the ideal tool for finding vulnerabilities before attackers do.
Join the Pingu Unchained waitlist →
Early access includes:
- 2.5 million tokens (limited-time offer)
- Priority queue for verified researchers and security professionals
- Access to the same adversarial techniques we use for Sora, GPT, Claude, and others
See the Full Profile
All videos (except the deleted Sam Altman videos) are still live on our Sora profile: https://sora.chatgpt.com/profile/ozgurozkan
Check it out before OpenAI decides to moderate retroactively.
The Bottom Line
Remixes are guarded. Fresh prompts are vulnerable. Enforcement is reactive, not proactive.
If you're deploying generative AI, assume attackers will test every edge case you haven't—and assume your safety filters have gaps. The only way to know where those gaps are is to test adversarially, at scale, with tools that mirror real attacker behavior.
That's what we built Audn.AI to do. If you're shipping AI, we'll break it before someone else does.
For offensive AI research and security testing: → Audn.AI Platform → Pingu Unchained Waitlist
Follow our research: → Twitter/X: @audn_ai → Sora Profile: ozgurozkan
Read More
Introducing Pingu Unchained: The Unrestricted LLM for High-Risk Research Access the same unrestricted AI model we used to jailbreak Sora 2, built specifically for red-teaming and security research without content filters.
Call Me a Jerk: What Persuasion Teaches Us About LLMs Wharton research shows how classic social influence tactics more than double compliance rates with objectionable requests in LLMs.
A Red Teaming Machine Social Engineers Another Machine Discover how Audn.AI built an autonomous voice red teaming system that successfully extracted secrets from protected AI agents.
Research conducted October 2025 by the Audn.AI security research team. Videos remain accessible on the Sora platform at time of publication (except the deleted Sam Altman videos). This research is published for defensive security purposes only.